목차

피어슨 상관관계(Pearson's Correlation)이란? 수식(Equation)
앞서 포스트에서 공분산(Covariance)에 대해 설명하였습니다(https://scribblinganything.tistory.com/714). 공분산의 특성은 아래와 같았습니다.
1. 공분산을 통해서 Postive, Negative, No trend의 관계를 확인할 수 있다.
2. 공분산의 결과 값 Cov[X,Y]의 크기를 통해서 공분산 정도가 크다라고 판단할 수는 없다.
3. 공분산 자체의 의미는 중요하지 않고 Correlation을 계산하기 위한 단계로 사용된다.
위 특성 처럼 Covariance와 두 데이터 간의 관계를 해석하는데 어려움이 있어서 Correlation을 사용합니다. Correlation의 수식은 아래와 같습니다.

상관관계(Correlation) 수식은 위와 같이 정리 됩니다. 공분산과 분산의 수식을 사용해서 상관관계 수식을 만듭니다. 그래서 앞서 공분산의 특성3이 성립하게 되는 것입니다.

그림1과 같이 5명의 학생의 몸무게와 키를 측정해서 좌표를 찍고 이를 예측하는 직선(Straight line)을 그립니다. 해당 라인을 통해서 다른 학생의 몸무게나 키 중에 하나의 값을 가지고 있으면 다른 값을 예측할 수 있습니다. 이를 "Educated Guess"라고 합니다.
Correlation은 해당 직선에 데이터가 얼마나 가깝게 올라가있는가 입니다. 데이터들이 직선 위에 다 올라가 있으면 상관관계가 아주 높으므로 하나의 변수로 상대 변수를 예측할 수 있는 것입니다.
피어슨 상관관계(Pearson's Correlation) 특징

그림2와 같이 기울기 값과는 관련 없이 라인 위에 데이터가 모두 배치되면 Correlation 값은 1을 가집니다. 그리고 기울기가 음수의 방향이고 데이터가 라인 위에 배치되면 -1을 가집니다. 이것이 Correlation의 첫번째 특징입니다.
1. 기울기 크기에 관계없이 데이터가 직선 라인에 배치되면 상관관계는 1, -1의 값을 가진다.
2. 상관관계는 -1~1 의 값만을 가진다.
앞서 수식1을 통해서 공분산이 Normalized 되어서 상관관계는 -1~1의 값을 가집니다. 이것이 두번째 특징입니다.
그리고 상관관계의 절대값이 1에 가까울 수록 Strong Relationship이라고 하고 0에 가까울 수록 Weak Relationship이라고 부릅니다. 상관관계가 Strong이라는 의미는 몸무게 변수로 키 변수의 값을 정확하게 예측이 가능하다는 의미 입니다.
앞서 그림2와 같이 2개의 샘플만을 사용해서 Correlation을 구하면 항상 1, -1이 나옵니다. 그렇다면 이 데이터를 믿을 수 있을까요? 신뢰(Confidence)를 처리하기 위해 사용되는 개념이 p value 입니다. 예전에 p value에 대한 정리를 하였는데 참조 하시길 바랍니다(https://scribblinganything.tistory.com/692). 추후에 p-value에 대해서 다시 정리하는 글을 올리겠습니다.

위 그림3의 Correlation은 둘다 1입니다. 하지만 왼쪽 그래프는 p-value가 1이고 오른쪽은 3x10^(-15)으로 p-value가 낮은 오른쪽 그림이 신뢰도가 높은 상관관계임을 알 수 있습니다. 즉, 왼쪽 그래프로 추가되는 입력에 대한 예측을 하게 되면 신뢰도가 낮아서 틀릴 확률이 높다는 의미 입니다.
3. 상관관계의 신뢰도는 p-value로 결정하고 p-value가 낮을 수록 믿을 만한 데이터입니다.
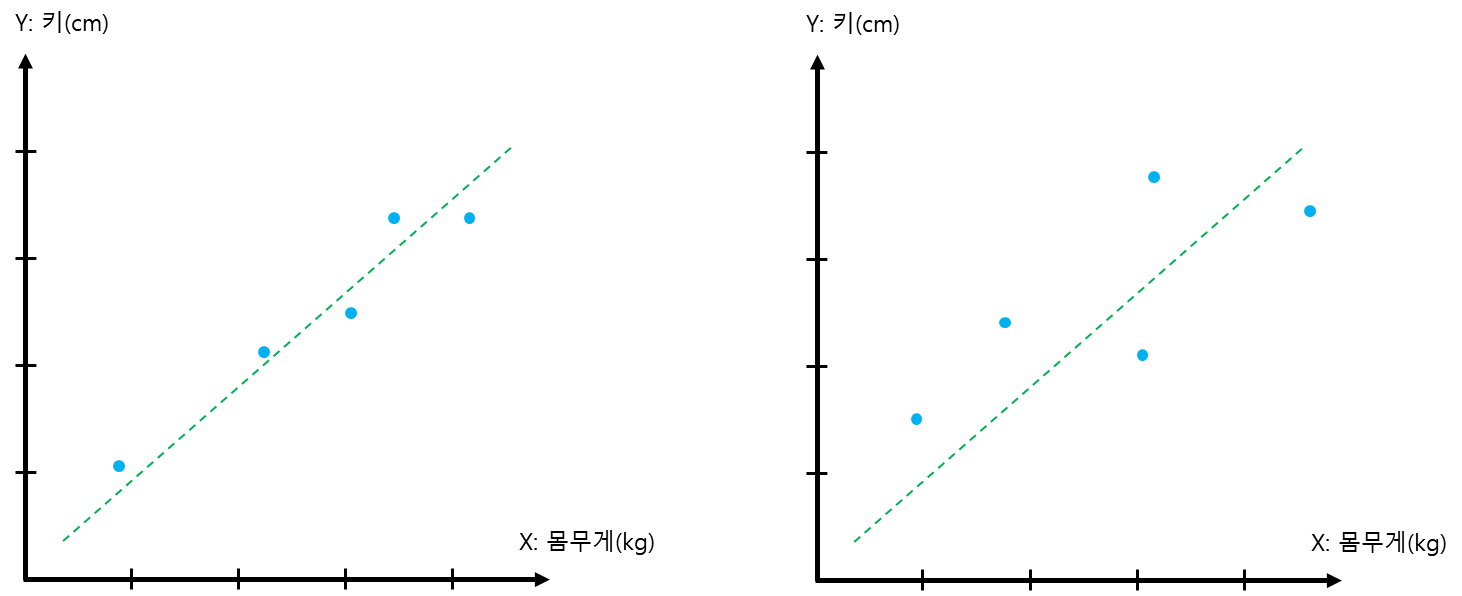
위 그림과 같이 왼쪽은 0.9을 오른쪽은 0.5정도의 Correlation value를 가진다고 하겠습니다. 그럼 과연 왼쪽이 오른쪽 그래프보다 약 2배에 가까운 예측율을 가진다고 할 수 있을까요? 그래프에서 느낄 수 있겠지만 그렇지 않습니다. 그래서 나온 개념이 R제곱 입니다. 해당 내용은 https://scribblinganything.tistory.com/693 를 참조하시면 됩니다.
4. Correlation값 비율이 예측도의 비율은 아닙니다.
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [머신러닝] K mean clustering이란? 예제로 이해하기(클러스터링) (0) | 2023.05.18 |
|---|---|
| [머신러닝]SVM(Support Vector Machines)이란? 예제와 수식풀이 (0) | 2023.05.17 |
| [머신러닝] 공분산(Covariance)란? 특징 및 사용 목적 (0) | 2023.05.13 |
| [머신러닝] 랜덤포레스트란? 쉬운예제로 이해하기(Random Forest, Bagging, Bootstrap) (0) | 2023.05.08 |
| [머신러닝]Regression Tree 가지치기(Prune) 예제로 쉽게 이해하기(Cost Complexity/Weakest Link Prunning) (0) | 2023.05.07 |