목차

Regression Tree 가지치기란?
앞서 회기형 트리에 대해서 배워보았습니다(https://scribblinganything.tistory.com/711).
회기형 트리(Regression Tree)를 만들때 모든 Training Data에 대해 세분화 해서 Node를 만들어서 분류를 하게 되면 Overfitting이 발생한다고 하였습니다. 이렇게 만들어진 트리 모델을 Test Data에 대입해 보면 Overfitting에서 RSS 값이 높게 나올 수 있습니다. 즉, Overfitting에 의해 Variance가 높아지는 것입니다.
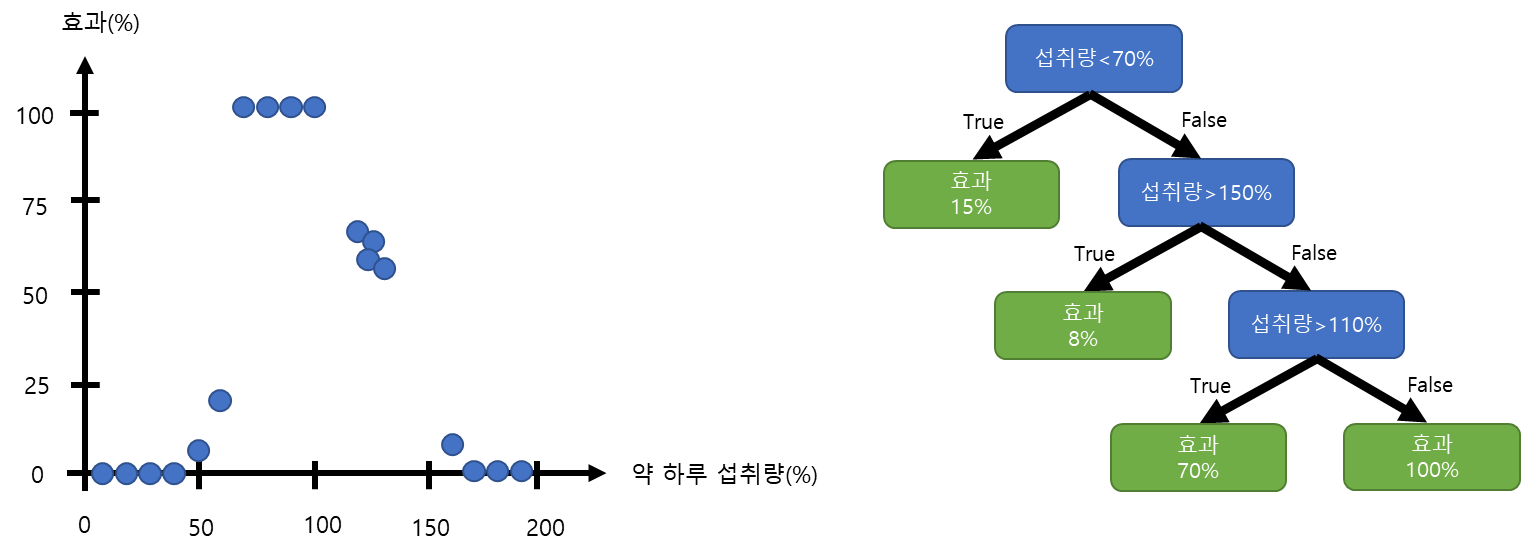
그림1과 같이 하루 약 섭취에 대한 효과의 데이터를 통해 회귀 트리(Regression Tree)를 오른쪽과 같이 만들 수 있습니다. 만드는 방법은 앞전 포스트를 참조하시면 됩니다.
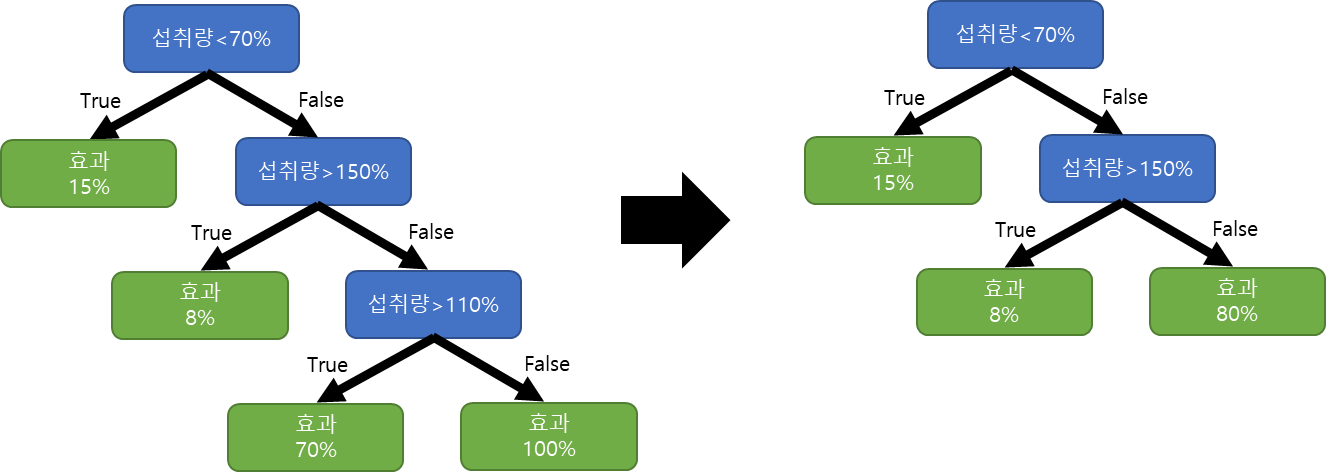
가지치키(Prunning)이란 그림과 같이 Internal Node와 Leaf Node의 묶음을 하나의 Leaf Node로 바꿔서 트리 모델을 심플하게 만드는 작업입니다.
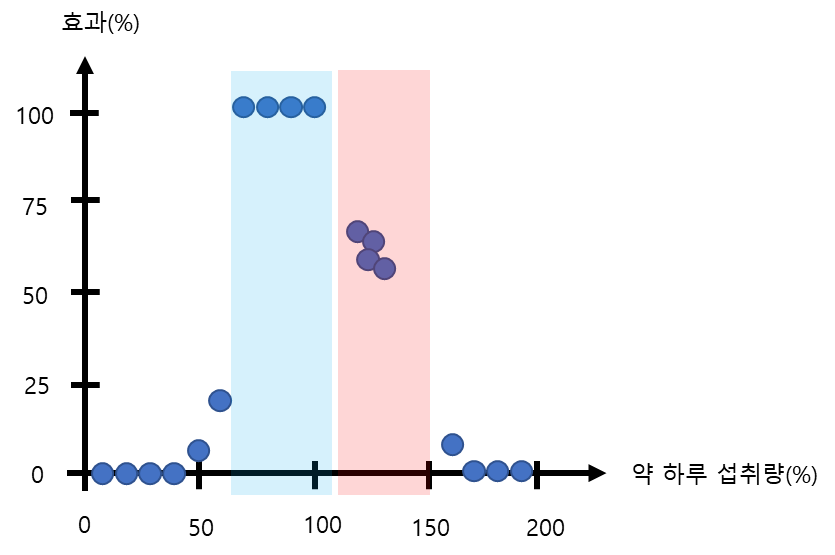
그림2와 같이 Prune을 진행하게 되면 그림3의 파란색 빨간색 영역으로 나눠서 분류했던 것을 합친 값의 평균을 사용하게 되는 것입니다.
그렇다면 그림1의 모델에서 가지를 쳐서 (Pruning) 만들수 있는 모델은 아래와 같이 가능 합니다.

그림4와 같이 총 4가지 모델로 표현이 가능 합니다.
이 중에 어떤 모델이 실제 Testing Data에서 에러 값이 작을까?
Cost Complexity (Weakest Link) Prunning으로 최적의 모델 찾기
앞서 검증에서 어떤 모델이 최적의 회기 트리 모델인지를 찾는 방법은 Cost Complexity Prunning으로 처리해보겠습니다.
Cost Complexity Prunning 의 요점은 RSS(Sum of Squared Residuals)을 통해서 모델을 비교하는 것입니다.

앞서 Prune으로 구할 수 있는 모델을 다 구해 봅니다. 위 그림5와 같이 각 leaf의 RSS 값을 구합니다. 이때 RSS는 모델의 효과 값에서 Training Data 값과의 차이를 제곱해서 더한 값입니다. 위 값들은 제가 실제 값들을 계산한 값이 아닌 대충 임의로 적은 것이니 개념 파악 용으로만 사용하십시오.
당연하게도 Prune을 하게 되면Training Data와의 Bias가 커지므로 SSR이 커지게 됩니다. 하지만 위 모델 중에 Testing Data와의 RSS이 더 적은 모델이 있을 수 있습니다.
이제 모델의 점수를 구하는 수식을 알아보겠습니다.
- Tree Score = RSS + α x (The no of leaf nodes)
그림에서 녹색 칸인 Leaf Node 에 알파를 곱하고 이 값을 앞서 구한 전체 RSS에 더해서 가장 작은 Score를 받은 트리가 선택 됩니다.
여기서 알파 값(α)은 스텝 파라미터 또는 Tunning 파라미터라고 합니다. 해당 알파 값에 의해 전체 트리 점수가 크게 좌우 되기 때문에 알파 값도 잘 선정해야 합니다.
알파 값은 어떻게 결정하는가?
우선 정답부터 얘기 드리면 CV(Cross Validation)을 사용해서 각 모델 별로 알파 값을 적용하고 가장 작은 RSS값을 가지는 알파 값을 선정 합니다. 그리고 그때의 모델을 선택해서 사용합니다.
알파 값을 구하는 과정을 순서대로 정리 해보겠습니다.
1. Traing 데이터와 Testing 데이터 모두 사용해서 회기 트리를 만듭니다.
2. 그림5와 같이 앞서 Prunning과정을 통해 나올 수 있는 모델을 만듭니다.
3. 가지치기를 하기전의 회기 트리는 RSS값이 가장 작습니다. 그러므로 알파가 0일때 첫번째 모델이 선택됩니다. 첫번째 알파 값으로 0을 선정합니다.
4. 두번째 알파는 가지치기를 한번 진행한 모델에 대해 해당 모델이 가장 작은 Tree Score를 가지는 알파로 선정 합니다.
5. 나머지 모델에 대해서도 4번 과정을 반복해서 모델의 수만큼 알파 값을 구합니다.
6. Cross Validation을 위해 1개의 Testing Data를 남기고 나머지 K-1개의 Data로 Training Data를 만들어 회기 트리 모델을 만듭니다.
7. 6번에서 만들어진 회기 트리를 가지치키를 진행하면서 앞서 3~5번 과정에서 구한 알파(0, ....)을 각 각 모델에 따로 적용합니다. 다르게 적용된 알파를 Testing Data에 적용해서 Tree Score를 구해줍니다..
8. 앞서 7번 과정을 K번 진행해서 각 각의 Testing Data에서 만나온 Tree Score의 평균을 구하고 가장 작은 값을 가지는 모델과 알파 값을 최종적으로 선택 합니다.
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [머신러닝] 공분산(Covariance)란? 특징 및 사용 목적 (0) | 2023.05.13 |
|---|---|
| [머신러닝] 랜덤포레스트란? 쉬운예제로 이해하기(Random Forest, Bagging, Bootstrap) (0) | 2023.05.08 |
| [머신러닝] Regression Tree란? 예제로 쉽게 이해하기 (0) | 2023.05.05 |
| [Classification] Decision Tree 예제 설명 #2 (노드 순서 정하기) (0) | 2023.05.04 |
| [Classification] Decision Tree 예제 설명 #1 (Gini Impurity) (0) | 2023.05.02 |