목차

랜덤포레스트(Random Forest)란?
Random Forest 는 Forest의 의미가 주듯이 트리를 모은 숲을 의미 합니다. 트리의 의미에 대해 알고 싶다면 아래 블로그 글부터 순차적으로 확인하시길 바랍니다(https://scribblinganything.tistory.com/709).
랜덤 포레스트를 사용하는 목적은 트리의 특성에 있습니다. 트리는 Training Data에서 높은 정확도(Accuracy)를 가지지만 Testing Data에서는 정확도가 떨어집니다(Inaccuracy). 랜덤포레스트는 이러한 트리들을 랜덤하게 형성해서 정확도(Accuracy)를 높이는 목적으로 사용됩니다.
랜덤포레스트(Random Forest) 모델 생성
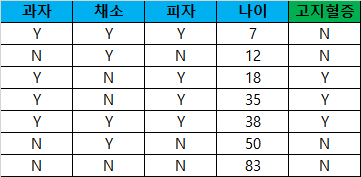
테이블1은 데이터셋으로 과자, 채소, 피자를 하루에 한번 먹으면 Yes, 아니면 No로 표기하였고 각 환자의 나이를 입력값으로 넣었습니다. 그리고 그에 따른 고지혈증을 가지고 있는지 여부에 대한 데이터 셋입니다.
1. 테이블1의 값을 랜덤으로 선택해서 동일한 데이터 사이즈로 만들어 줍니다. 이때 같은 데이터를 한번 이상 선택 가능 합니다. 이러한 방식을 부트스트랩(Boot Strap)이라고 합니다. 부트스트랩으로 아래 테이블2가 만들어졌습니다.

2. 부트스트랩(Bootstrap)으로 생성한 테이블2에서 Column에 대한 서브셋(Subset)을 랜덤으로 선택합니다. 서브셋에 들어가는 Column의 수의 결정은 잠시후에 설명하고 여기서는 두 개의 Column을 가지는 서브셋을 선택하도록 하겠습니다. 랜덤으로 과자와 피자가 선택되었다고 하겠습니다. 다음으로 지니 불순도(Gini Impurity)와 같은 방법을 사용해서 불순도가 낮은 값을 Root Node로 선택 합니다.
이번 예제는 피자가 지니 불순도가 낮다고 가정하고 아래와 같이 Root Node 를 결정합니다.

다음으로 피자를 제외한 과자, 채소, 나이 중에 2개의 Column을 Random 하게 선택합니다. 이런 식으로 앞서 배운 Decision Tree 방법과 같이 트리를 완성합니다.
3. 다시 1번 단계로 가서 Original Data Set으로 부터 부트스트랩으로 새로운 데이터를 만들고 2번 과정을 진행합니다. 반복 횟수만큼의 다양한 트리가 완성됩니다. 이번 예제는 100번의 반복을 통해 100개의 트리를 만들었다고 가정하겠습니다.
4. 이제 만들어진 모델을 통해 예측을 해보겠습니다.

테이블3과 같은 조건의 사람의 고지혈증을 예측해봅니다. 1~100번의 트리 모델에 해당 입력값을 넣고 결과를 정리해봅니다.
이번 예제에서 80개의 트리는 고지혈증 예측을 No로 했고 20개의 트리는 고지혈증 예측을 Yes라고 했다고 하겟습니다. 그럼 다수가 No이므로 테이블3의 예측은 No가 됩니다.
위와 같이 Bootstrapping한 데이터를 사용해서 예측치를 모아서(aggreate) 결과를 예측하는 방식을 Bagging이라고 합니다. 알파벳의 앞자를 사용해서 만든 단어입니다.
랜덤포레스트(Random Forest) 모델 평가
앞서 테이블2와 같이 부트스트랩으로 다시 데이터를 만들때 확률적으로 Original Dataset의 약 1/3 정도는 부트스트랩으로 만든 데이터에 포함되지 않습니다.

앞서 테이블3에 포함되지 않은 값은 위 테이블4와 같습니다. 이와 같이 부트스트랩에 포함되지 못한 값들을 "Out of Bag Dataset"이라고 부릅니다.
앞서 예제에서 100번의 반복으로 부트스트랩데이터셋을 만들었습니다. 여기서 발생한 Out of Bag Dataset을 해당 트리에 적용해서 예측과 결과를 비교해봅니다. 예를 들어 고지혈증 결과값은 N인데 트리에 적용한 값이 6개가 N를 예측하고 1개가 Y로 예측한 경우 1/(6+1) 을 "Out of Bag Error"라고 부릅니다. 즉, 잘못 분류할 비율(Incorrectly classified's proportion)입니다.
Column 개수 선정방법
앞서 예제에서는 2개의 Column을 랜덤하게 선택해서 트리의 Node를 만들었습니다. 실제 알고리즘은 Column의 변수에 대한 분석도 필요합니다.
1. 랜덤 포레스트를 만듭니다.
2. Out of Bag Error를 계산해서 모델을 평가합니다.
3. Column의 변수를 변경하고 다시 1번을 진행합니다.
1번에서 랜덤 포레스트를 만들때 일반적으로 Column의 제곱한 수만큼 부트스트랩과 트리를 만들어서 평가를 합니다.
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [머신러닝]Correlation이란? Covariance 차이, 수식, 사용 목적(피어슨 상관관계) (0) | 2023.05.16 |
|---|---|
| [머신러닝] 공분산(Covariance)란? 특징 및 사용 목적 (0) | 2023.05.13 |
| [머신러닝]Regression Tree 가지치기(Prune) 예제로 쉽게 이해하기(Cost Complexity/Weakest Link Prunning) (0) | 2023.05.07 |
| [머신러닝] Regression Tree란? 예제로 쉽게 이해하기 (0) | 2023.05.05 |
| [Classification] Decision Tree 예제 설명 #2 (노드 순서 정하기) (0) | 2023.05.04 |