목차

sklearn 설치 하기
저는 Visual Studio에서 파이썬 실습을 하고 있기 때문에 Visual Studio에서 sklearn을 설치하도록 하겠습니다.
PS D:\Python\test05> pip install sklearn
Requirement already satisfied: sklearn in c:\users\forgo\appdata\local\programs\python\python38\lib\site-packages (0.0.post1)
[notice] A new release of pip available: 22.2.2 -> 22.3.1
[notice] To update, run: c:\users\forgo\appdata\local\programs\python\python38\python.exe -m pip install --upgrade pip
위와 같이 pip install sklearn을 하게 되면 에러 메세지도 뜨지 않고 위와 같이 종료 됩니다. 사실 라이브러리는 sklearn으로 사용하지만 설치 시 다른 이름을 사용하여야 합니다.
pip install scikit-learn
위와 같이 scikit-learn 을 설치하여야 정상 설치가 됩니다.
파이썬 선형회기(Linear Regression) 예제 실습
이번에는 앞서 설치한 sklearn 라이브러리로 선형 회기 모델을 실행해보겠습니다. 이번 실습은 간단하게 선형회기를 실습하고 예제 코드를 설명하는 차원에서 진행하겠습니다. 다음 포스트는 선형 회기에 대한 자세한 설명과 함께 실습을 진행해보겠습니다.
예제 코드를 간단하게 설명 드리면 넘파이(Numpy) 랜덤함수를 사용해서 x, y 값을 50개 씩 생성 합니다. 이때 y 값은 x에 선형하게 나오게끔 x에 0.7~1.2사이의 임의의 수로 곱해 줍니다.
이렇게 나온 랜덤 값을 판다스(Pandas)의 데이터 프레임(Dataframe)으로 만들어서 선형회기 선을 예측해봅니다. 그리고 예측 값과 랜덤으로 추출한 값을 matplotlib 그래프를 사용해서 비교해보겠습니다.
예제 전체 코드>>
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import pandas as pd
from numpy import random
data_set = []
y_list = []
for _ in range(50):
x_val = random.randint(1,10)
mul = random.uniform(0.7,1.2)
y_val = x_val*mul
data_set.append([x_val, y_val])
df=pd.DataFrame(data_set, columns=['x_value','y_value'])
print(df)
x = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
L_reg = LinearRegression()
L_reg.fit(x, y)
y_pre = L_reg.predict(x)
#그래프 그리기
plt.title('Regression')
plt.xlabel('x value')
plt.ylabel('y value')
plt.scatter(x, y)
plt.plot(x, y_pre, color='red')
plt.show()
결과>>
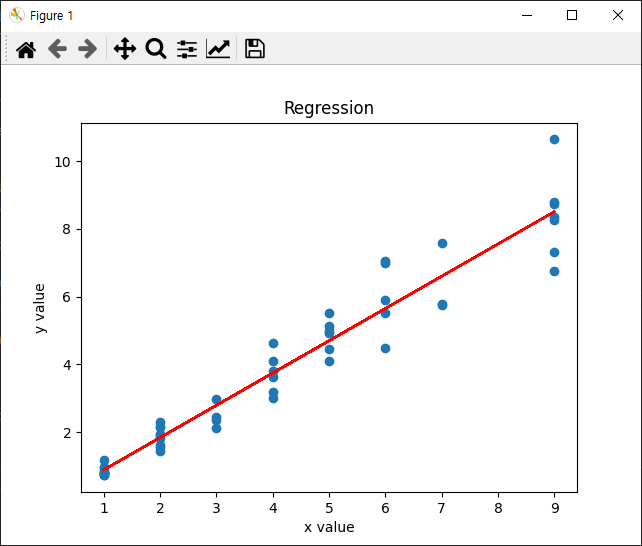
주석>>
data_set = []
y_list = []
for _ in range(50):
x_val = random.randint(1,10)
mul = random.uniform(0.7,1.2)
y_val = x_val*mul
data_set.append([x_val, y_val])
df=pd.DataFrame(data_set, columns=['x_value','y_value'])
print(df)numpy 랜덤함수 randint와 uniform을 사용해서 x 값은 1~10으로 y 값은 x 값에 0.7~1.2 사이 실수로 곱해서 구합니다.
랜덤으로 채워진 값은 판단스 DataFrame을 사용해서 값을 채웁니다.
x = df.iloc[:, :-1].values
y = df.iloc[:, -1].valuesx값은 행(Row)은 모든 값을 가져오고 열(Column)은 마지막 값에서 앞에 값을 가져 옵니다.
y값은 행(Row)은 모든 값을 가져오고 열(Column)은 마지막 값을 가져 옵니다.
L_reg = LinearRegression()
L_reg.fit(x, y)
y_pre = L_reg.predict(x)선형회기 객체를 LinearRegression으로 만들어 줍니다. 객체의 fit 함수를 통해 데이터를 1차식 라인으로 최적화된 선을 그어 줍니다. 그리고 x값을 넣었을 때 나올 수 있는 값을 y_pre에 넣어 줍니다.
plt.title('Regression')
plt.xlabel('x value')
plt.ylabel('y value')
plt.scatter(x, y)
plt.plot(x, y_pre, color='red')
plt.show()matplot 로 그래프를 그려 줍니다. 기존의 랜덤값은 scatter로 점으로 표현하고 선형회기에서 나온 예상 값은 선으로 만들어 줍니다.
'파이썬(Python) > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [Python] sklearn 정규 분포 만들기(StandardScaler), 그래프 비교 (0) | 2023.02.16 |
|---|---|
| [Python] sklearn 파이프라인(Pipeline) + ColumnTransformers (0) | 2023.02.14 |
| [Python] sklearn ColumnTransformer이란? 예제 실습(SimpleImputer, fit_transform) (0) | 2023.02.07 |
| [Python] sklearn 경사하강법(Gradient Descent)란? 사용방법 및 예제 실습(SGD) (2) | 2023.01.09 |
| [Python] sklearn train_test_split 사용법, Syntax, 예제 (0) | 2023.01.05 |