목차

일반화(Generalization), 과적합(Overfitting, Underfitting) 이란?
일반화(Generalization)
머신러닝에서 Generalization(일반화)은 모델이 학습 데이터에 대해 학습한 후, 이전에 본 적 없는 새로운 데이터에 대해 정확하게 예측할 수 있는 능력을 말합니다. 예를 들어 앞서 선형 회기(Linear Regression)에서 가지고 있는 데이터 셋을 사용해서 파라미터들을 유추해서 모델링을 만들어 이 후에 발생하는 입력에 대한 출력을 예측 가능하게 하는 것을 의미합니다.
과적합(Overfitting/Underfitting)
일반적으로 머신러닝 모델을 학습시키는 과정에서는, 훈련 데이터셋을 사용하여 모델의 가중치(Weights)를 조정하고 최적화를 수행합니다. 이렇게 학습된 모델은 훈련 데이터(Training Data)에 대해서는 높은 정확도를 보이지만, 이전에 본 적 없는 데이터(Test Data)에 대해서는 제대로 예측하지 못할 수 있습니다. 이러한 현상을 과적합이라고 합니다.
과적합에도 과대적합(Over Fitting)과 과소적합(Under fitting)이 있습니다.
과대 적합이란 Training 과 Test 사이에 에러 차이가 클때를 말합니다. 주로 데이터의 양이 많을 때(High Capacity) 발생합니다.
과소 적합이란 Training에서 모델이 충분히 낮은 에러를 획득하지 못한 경우를 말합니다. 주로 데이터 양이 적을 때(Low Capacity) 발생합니다.
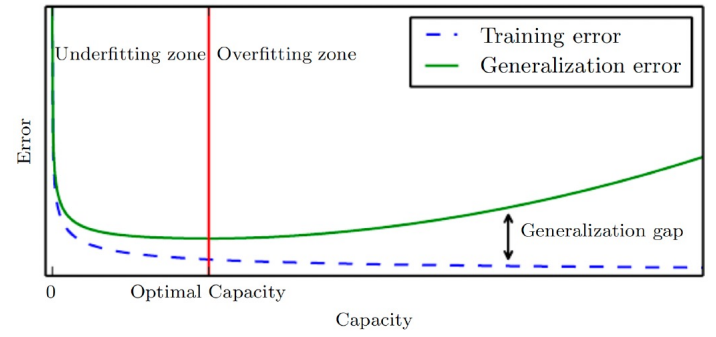
Generalization을 향상시키기 위해서는, 모델이 학습 데이터를 외워버리지 않고, 일반적인 패턴과 규칙을 학습하도록 해야 합니다. 이를 위해서는, 모델의 복잡성을 줄이는 것이 중요합니다. 예를 들어, 신경망 모델에서는 드롭아웃(Dropout) 등의 Regularization 기법을 사용하여 가중치에 제약을 두고, 모델이 과적합되지 않도록 합니다.
또한, 일반화를 향상시키기 위해서는 훈련 데이터셋을 다양하게 구성하고, 모델의 하이퍼파라미터(Hyperparameters)를 최적화하는 것이 중요합니다. 이렇게 함으로써, 모델이 일반적인 패턴을 학습하게 되고, 새로운 데이터에 대해서도 정확한 예측을 수행할 수 있게 됩니다.
참고로 Hyperparameter란 NN에서 활성화함수(Activation Function)에 사용된값과 같이 학습 알고리즘에 영향을 주는 매개변수 입니다. 앞서 포스트에서 활성화 함수를 모델링 특성에 따라 맞춰서 사용했습니다.(ex, 로지스틱, 소프트맥스)
일반화 과적합 파이썬(Python) 예제
아래 코드는 3차원 다항식의 형태로 나오는 데이터에 대해서 모델링하는 코드 입니다. 3차원 형태의 데이터는 선형 모델로 모델링하는 것에 한계가 있기 때문에 Quadratic Regression으로 모델링할 필요가 있습니다.
아래는 3차원 데이터에 대한 과적합에 대한 예제 입니다.
예제 코드>>
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
# 3차 다항식 데이터 생성
np.random.seed(0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))
y = np.sin(2 * np.pi * X) + 0.1 * np.random.randn(n_samples)
# 학습 데이터셋과 테스트 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Polynomial 회귀 모델 학습 및 예측 (Underfitting)
degree = 1
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X_train.reshape(-1, 1), y_train)
y_pred_train = model.predict(X_train.reshape(-1, 1))
y_pred_test = model.predict(X_test.reshape(-1, 1))
# MSE 및 R2-score 계산
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
# 그래프 그리기
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(X_train, y_train, s=20, edgecolor="black", c="darkorange")
plt.plot(X_train, y_pred_train, color="cornflowerblue", label=f"degree={degree}\nMSE={mse_train:.2f}, R2={r2_train:.2f}")
plt.title("Underfitting (High Bias)", fontsize=14)
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
# Polynomial 회귀 모델 학습 및 예측 (Overfitting)
degree = 10
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X_train.reshape(-1, 1), y_train)
y_pred_train = model.predict(X_train.reshape(-1, 1))
y_pred_test = model.predict(X_test.reshape(-1, 1))
# MSE 및 R2-score 계산
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
# 그래프 그리기
plt.subplot(1, 2, 2)
plt.scatter(X_train, y_train, s=20, edgecolor="black", c="darkorange")
plt.plot(X_train, y_pred_train, color="cornflowerblue", label=f"degree={degree}\nMSE={mse_train:.2f}, R2={r2_train:.2f}")
plt.title("Overfitting (High Variance)", fontsize=14)
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.tight_layout()
plt.show()
결과>>
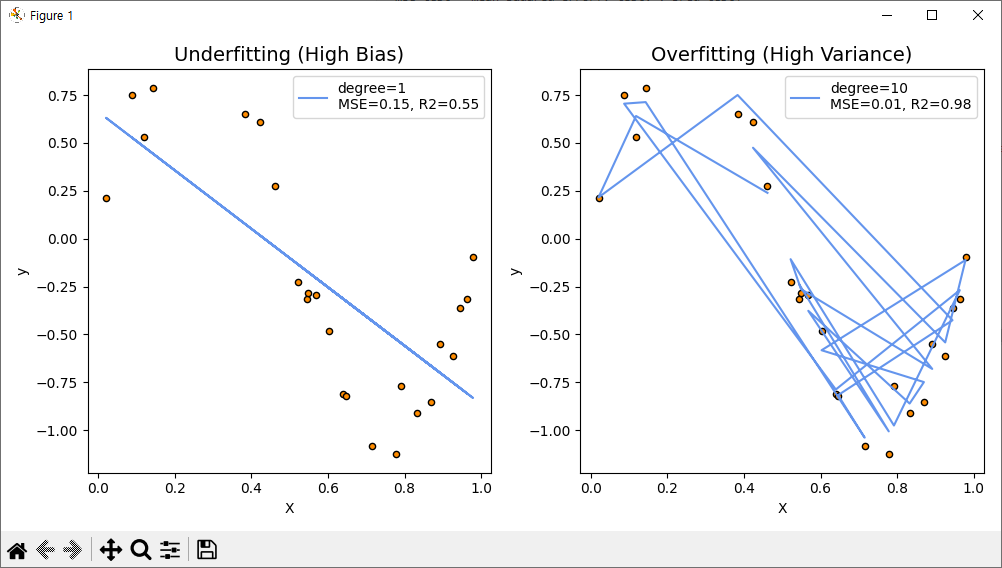
앞서 그림1과 같이 Underfitting에서 MSE 에러 값이 높게 나옵니다. Overfitting은 그래도 에러 값은 작게 나오고 R제곱(https://scribblinganything.tistory.com/693) 값은 1에 가깝게 나와서 괜찮은 모델링이라고 할 수 있습니다. 데이터가 더 복잡해질 경우 Overfitting이 안맞기 시작할 건데 이 경우는 그래도 잘맞게 나왔습니다.
예제 코드 다운로드>>
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [머신러닝] k-fold cross validation이란? 파이썬 예제 실습 (0) | 2023.03.31 |
|---|---|
| [머신러닝] 편형(Bias)와 분산(Variance)란? 파이썬 예제 코드로 이해하기(Trade off) (0) | 2023.03.31 |
| [Python] 원핫인코딩(One Hot Encoding)이란? 쉬운 예제로 실습하기 (0) | 2023.03.30 |
| [머신러닝]소프트맥스 회귀란?(Softmax Regression) (0) | 2023.03.23 |
| [머신러닝]로지스틱회귀란?(Logistic Regression, 시그모이드 함수) (0) | 2023.03.19 |