목차

해당 포스트(Machine Learning)는 유투브 혁펜하임의 강의 내용을 듣고 제 생각대로 정리한 내용이라 틀린 내용이 있을 수 도 있습니다.
Machine Learning 로지스틱회귀란?(What is Logistic Regression?)
앞서 퍼셉트론(Perceptron)에 대해 살펴 보았습니다(https://scribblinganything.tistory.com/674). 퍼셉트론이란 활성화 함수에 스텝 함수를 넣어서 -1 아니면 1이 되게 출력을 하였습니다.
로지스틱 회귀는 퍼셉트론과 유사한데 활성화 함수에 넣는 값이 Step Function이 아닌 시그모이드 함수(Sigmoid Function)를 넣어서 출력을 처리 합니다.

위 그림과 같은 형태가 시그모이드 함수의 그래프 입니다. 그래프를 수식으로 표현하면 아래와 같습니다.
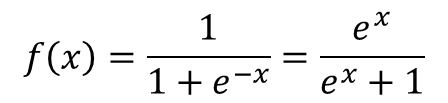
x 값에 따라 1이나 0에 가까운 출력을 내줍니다. 앞서 스텝함수와 다르게 값에 따라 0~1 사이 값으로 가깝게 출력되기 때문에 확률적인 접근이 가능합니다.
앞서 배운 선형회기(Linear Regression)의 경우 Loss 함수를 제곱의 합으로 최소값을 찾았습니다(https://scribblinganything.tistory.com/670). 이 경우 기울기와 절편을 구하는 선형(linear)에 관한 식이었기 때문에 Loss 함수가 단순히 2차 그래프의 형태로 최저값을 확인할 수 있었습니다.
하지만 로지스틱 회기의 경우 시그모이드 함수에 의해 출력이 구해지기 때문에 구하고자 하는 파라미터가 선형이 아닙니다. 그래서 Loss 함수에서 단순 Gradient로 구할수는 없습니다.
그래서 사용하는 방법이 Likelihood 방식으로 Loss 의 최저점을 구합니다.
로지스틱 회귀: Likelihood와 Loss 함수
우선 Likelihood에 대해 알아보겠습니다.

위 그림과 같이 박스 a, b, c에 빨간 구슬, 파란 구슬이 있을 경우 조건부 확률밀도 함수는 아래와 같이 구할 수 있습니다.
p(빨|박스a) = 3/4
p(파|박스a) = 1/4
즉, 박스 a를 선택했을 조건에서 구술이 빨간색이냐 파란색이냐 나올 전체 확률의 합은 항상 1이 되는 것이 조건부 확률 밀도 함수 입니다.
Likelihood는 파란색 구슬을 뽑는데 박스가 바뀌었을때의 확률과 같은 값입니다. 즉, 위의 조건부 확률밀도 함수에서 앞에 값은 고정이고 뒤에가 바뀔때입니다.
p(파|박스a) = 1/4, p(파|박스b) = 1/3, p(파|박스c) = 1/2
Likelihood는 합이 1이 되지 않습니다.
로지스틱 회기 Loss 함수
여자를 인식하는 머신러닝 로지스틱 회기 알고리즘(Logistic Regression Algorithm)을 작성했다고 가정하겠습니다. 해당 알고리즘의 Loss 함수를 구하는 과정을 통해 로지스틱 회기 Loss 함수의 동작에 대해 알아보겠습니다.
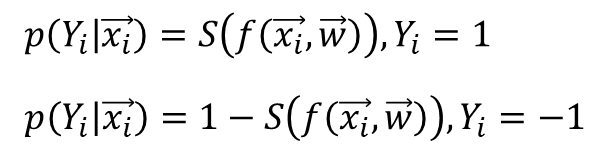
Yi는 라벨링(Labeling)이 된 값으로 여자 사람의 사진은 1로 표기하고 나머지 사진은 -1로 표기 합니다. 즉, 선형 회기 처럼 데이터 학습을 위해 필요한 데이터 입니다.
p(Yi|xi) 함수는 확률 밀도 함수로 xi라는 이미지를 넣었을 때 실제 이미지가 원하는 Yi로 출력되었는지를 확률로 확인하는 것입니다.
수식1의 첫번째 의미는 여자 사람의 이미지를 벡터 형태 xi로 넣고 NN에서 weight되서 출력된 값을 시그모이드 함수 S를 통과하면 0~1 사이 확률 값이 나옵니다. 실제 사용자는 여자 이미지라는 것을 알고 있기 때문에 Yi=1이 됩니다.
수식2의 두번째 수식은 여자 사람의 이미지가 아닌 사진을 넣고 확률을 살펴 보는 것입니다. 시그모이드를 통과한 확률 값이 0에 가까워야 여자 사람이 아닌 것으로 인식하고 1에 가까운 확률로 맞추게 됩니다.
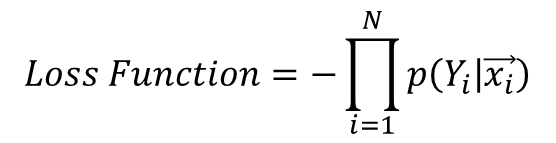
최종적으로 Loss 함수는 위와 같이 표기 됩니다. xi의 이미지를 바꾸면서 학습을 시키고 나오는 출력 확률의 합이 클 수록 정확하게 예측을 하기 때문에 앞에 음수 기호를 넣어서 클수로 음의 값이 커지므로 Loss 함수로 바꿀 수 있게 됩니다.
그리고 확률의 곱으로 표기한 이유는 xi 이미지를 넣는 것은 독립적인 동작이므로 확률을 곱해서 표기 해도 됩니다.
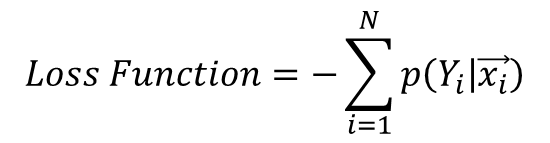
수식2는 곱으로 표현되기 때문에 이를 보기 편하게 Log 스케일로 수식3과 같이 변환하여 사용하기도 합니다. Loss의 최저점을 확인하는 것에는 수식2와 수식3 모두 동일하기 때문에 상황에 맞춰 사용하면 됩니다.
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| [Python] 원핫인코딩(One Hot Encoding)이란? 쉬운 예제로 실습하기 (0) | 2023.03.30 |
|---|---|
| [머신러닝]소프트맥스 회귀란?(Softmax Regression) (0) | 2023.03.23 |
| [머신러닝]퍼셉트론(Perceptron)이란? (MLP(Multi Layer), 활성화 함수, 사용목적, 풀이) (0) | 2023.03.08 |
| [머신러닝] 인공 신경망이란?(ANN, Artificial Neural Network), 예제 풀이(Example) (0) | 2023.03.04 |
| [머신러닝]경사하강법 미분 수식 풀이(Gradient Descent), 벡터 미분, Loss 함수, 학습률(Learning rate, Newton-Raphson) (0) | 2023.03.01 |