

Min Hashing이란?
Min-Hashing은 대규모 집합을 짧은 서명(signature)으로 변환하는 기법이며, 이 과정에서 원래 집합 간의 유사성을 보존하는 것을 목표로 합니다. 이 방법은 특히 대용량 데이터에서 유사한 항목을 효율적으로 비교하기 위해 사용됩니다.
1. 0/1 벡터 인코딩
전체 집합(universal set)의 각 원소에 대해, 해당 원소가 주어진 집합에 포함되면 1로, 그렇지 않으면 0으로 표시하는 벡터로 집합을 표현합니다.
>> 예를 들어, 전체 집합이 {A, B, C, D}이고, 주어진 집합이 {A, C}라면, 이 집합은 [1, 0, 1, 0]으로 표현됩니다.
2. 집합 연산의 비트 연산으로의 해석
집합 교집합: 두 집합의 교집합은 두 집합에 공통으로 포함된 원소들의 집합입니다. 비트 연산에서는 이를 "비트별 AND 연산"으로 해석할 수 있습니다. 두 벡터의 동일한 위치에 있는 비트가 모두 1일 경우에만 결과 벡터의 해당 위치의 비트가 1이 됩니다.
>> 예: [1, 0, 1, 0] AND [0, 1, 1, 0] = [0, 0, 1, 0] (C 원소만 공통)
집합 합집합: 두 집합의 합집합은 두 집합의 모든 원소를 포함하는 집합입니다. 비트 연산에서는 "비트별 OR 연산"으로 이를 해석할 수 있습니다. 두 벡터의 동일한 위치에 있는 비트 중 하나라도 1이면 결과 벡터의 해당 위치의 비트가 1이 됩니다.
>> 예: [1, 0, 1, 0] OR [0, 1, 1, 0] = [1, 1, 1, 0] (A, B, C 원소 포함)
3. 해싱
집합의 각 원소에 대해 여러 해시 함수를 적용하여, 각 원소를 해시 값으로 변환합니다. 이러한 해시 값들은 원본 데이터의 축약된 표현을 제공합니다.
4. 최소값 선택
각 해시 함수에 대해, 변환된 해시 값들 중 최소값을 선택합니다. 이 최소값들은 해당 집합의 "서명"을 구성합니다. 여러 해시 함수를 사용함으로써, 각 집합은 고유한 서명을 갖게 됩니다.
5. 유사성 비교
두 집합의 서명(최소 해시 값들의 집합)을 비교함으로써, 원본 집합 간의 유사성을 효율적으로 평가할 수 있습니다. 서명 간의 유사도가 높을수록, 원본 집합들도 더 유사하다고 볼 수 있습니다.
Min-Hashing은 주로 대용량 텍스트 데이터 또는 사용자 행동 데이터 같은 곳에서 유사한 아이템을 찾거나, 중복을 제거하는 데 사용됩니다. 예를 들어, 두 문서가 얼마나 비슷한지 빠르게 판단하거나, 사용자가 좋아할 만한 비슷한 상품을 추천하는 시스템에 활용됩니다.
장점
- 효율성: 대규모 데이터 집합 간의 유사성을 비교할 때, 원본 데이터를 직접 비교하는 것보다 훨씬 적은 계산량으로 비교가 가능합니다.
- 유사성 보존: Min-Hashing은 원본 집합의 유사성을 잘 보존하는 서명을 생성합니다. 따라서, 서명을 비교함으로써 원본 데이터의 유사도를 간접적으로 추정할 수 있습니다.
Min Hashing 예제 실습#1
D1 = "aacbba" Document에서 k = 2인 Shingles로 Set을 구하면 아래와 같습니다.
S(D1) = {aa, ac, ba, bb}
다음으로 hash로 Shingles를 간단하게 표현하겠습니다.
0 = aa
1 = ab
2 = ac
3 = ba
4 = bb
위와 같이 5가지에 대해 hash를 정의하면 아래와 같이 표현할 수 있습니다.
D1을 벡터 인코딩을 사용해서 C1으로 변환하면 아래와 같습니다.
C1 = 10111
0은 해당 값이 없다는 의미 입니다.
C2 = 10011 으로 가정하겠습니다.
C1과 C2의 교집합과 합집합의 수는 아래와 같이 구할 수 있습니다.
Size of intersection = 3, size of union = 4
Jaccard similarity를 구하면 아래와 같습니다.
sim(C1, C2) = 3 / 4
이를 거리로 변환하면 아래와 같습니다.
d(C1,C2) = 1 - (Jaccard similarity) = 3/6
Min Hashing 예제 실습#2
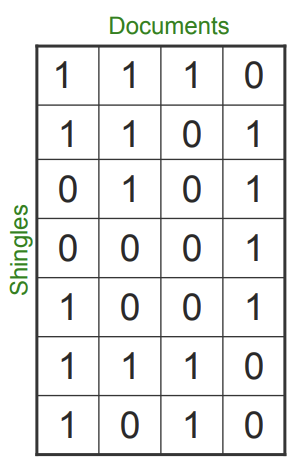
위 그림과 같이 Document와 Shingles가 정리되어있다고 가정하겠습니다. Document를 벡터 변환한 C1을 첫번째 열이고 C2는 두번째 열입니다.
유사성(Simularity)를 구하면 아래와 같습니다. 이때 주의할 점은 0, 0은 set이 없다는 의미 입니다.
Size of intersection = 3, size of union = 6
Sim(C1, C2) = 3/6
Min Hashing 예제 실습#3
이제 Min Hashing에서 Hashing을 사용해서 데이터의 사이즈를 줄이고 유사성(Similarity)도 크게 변하지 않는 C를 찾아 보겠습니다.
이번 실습의 목표는 아래 조건을 만족 하는 Hash Function을 찾는 것입니다.
- if sim(C1,C2) is high, then with high probability of h(C1) = h(C2)
- if sim(C1,C2) is low, then with high probability of h(C1) ≠ h(C2)
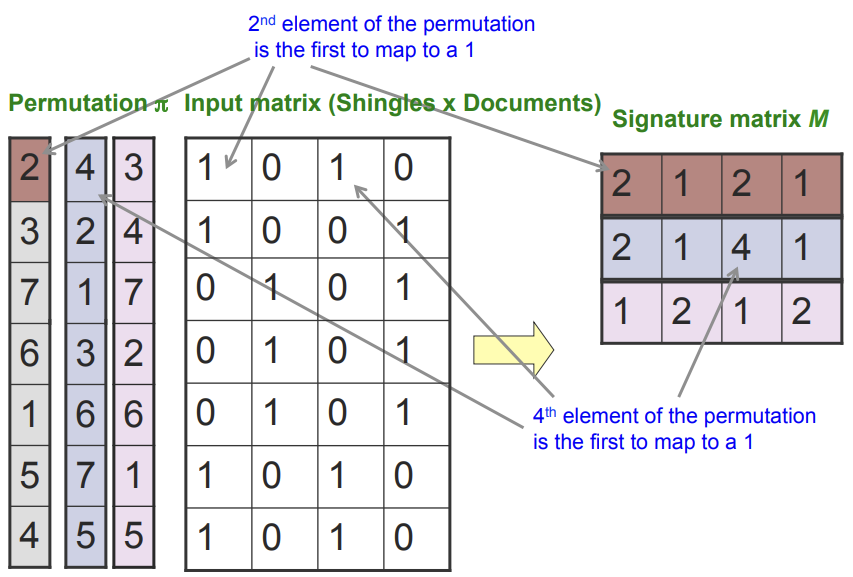
위 그림은 앞서 예제2의 Shingles X Document 행렬을 사용해서 Hash를 이용해서 Signature 행렬을 만드는 과정입니다.
우선 랜덤하게 순열(Permutation)을 만듭니다. 여기서는 3개의 순열을 만들었습니다. 3개의 순열은 Signature 행렬의 3개의 Shingles로 바뀌게 됩니다.
Permutation의 1부터 순차적으로 검색해서 1이 나올때까지 찾습니다. 1이 나오면 해당 index 번호를 Signature 행렬에 기록 합니다.
위 과정을 반복해서 Signature 행렬을 완성 합니다.
이렇게 만들어진 Signature 행렬과 기본 행렬의 Similarity를 비교하면 아래와 같습니다.
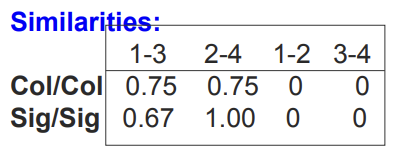
Col/Col 은 기본 테이블의 Document를 비교해서 Similarity를 계산한 것이고 Sig/Sig는 Signature 행렬을 사용해서 Similarity를 계산한 것입니다.
위와 같이 Similarity 테이블를 다른 Permutation 조합으로 만들어서 유사성 값이 비슷한 형태의 Hash 함수를 만듭니다.
'여러가지공부 > 머신러닝(Machine Learning)' 카테고리의 다른 글
| 자카드 거리/유사도란? 예제로 이해하기 (Jaccard, distance, similarity) (0) | 2024.03.20 |
|---|---|
| [LSH]K Shingling(K gram)이란?(Locality Sensitive Hashing#1) (0) | 2024.03.19 |
| 시간 복잡도 O(n^2)이란?(Time Complexity) (1) | 2024.03.15 |
| [Neural Networks] NN의 Backpropagation이란? 예제와 함께 설명#1 (0) | 2023.06.27 |
| [Neural Networks] NN이란? 구성 및 forward propagation 동작 방식 (0) | 2023.06.26 |